Submitted by LutherXD 70 EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience meituan 147 2
Submitted by freesky 60 HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding OpenMOSS 29 4
Submitted by nzl-thu 59 The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models Tsinghua-LeapLab 68 5
Submitted by daixuancheng 56 LLM-in-Sandbox Elicits General Agentic Intelligence Microsoft Research 63 4
Submitted by LiamLian0727 51 BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries Zhongguancun Academy 14 4
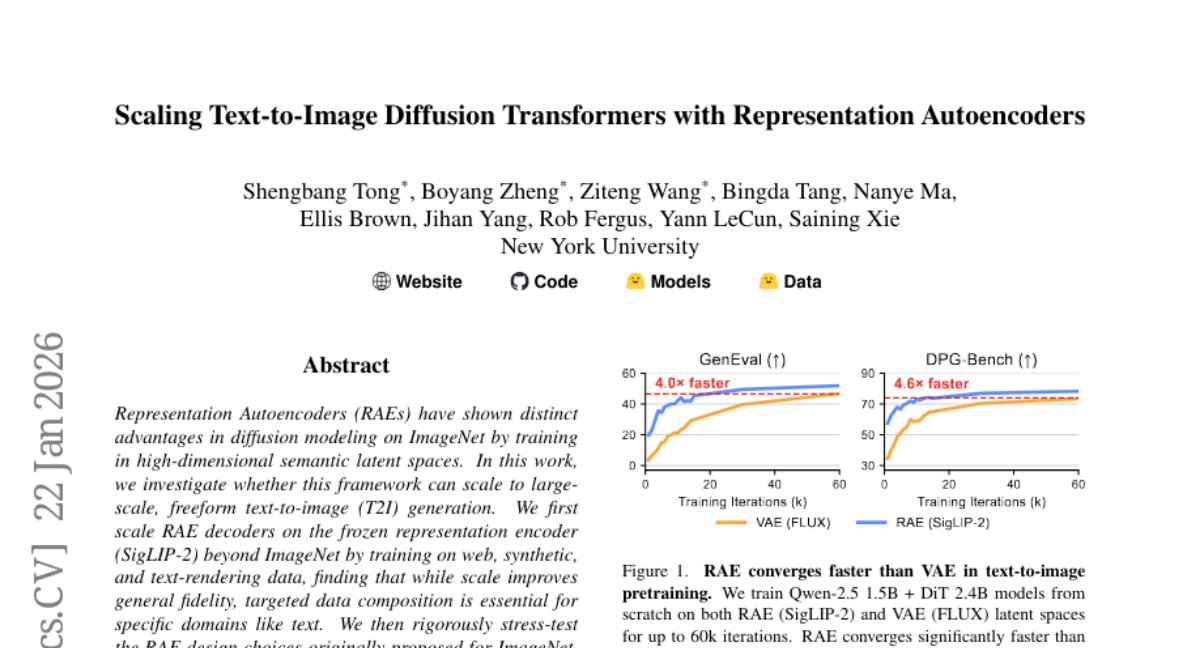
Submitted by bytetriper 44 Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders VISIONx @ NYU 107 2
Submitted by Facico 44 Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model ByteDance Seed 21 1
Submitted by taesiri 21 Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces · 85 authors 1.41k 1
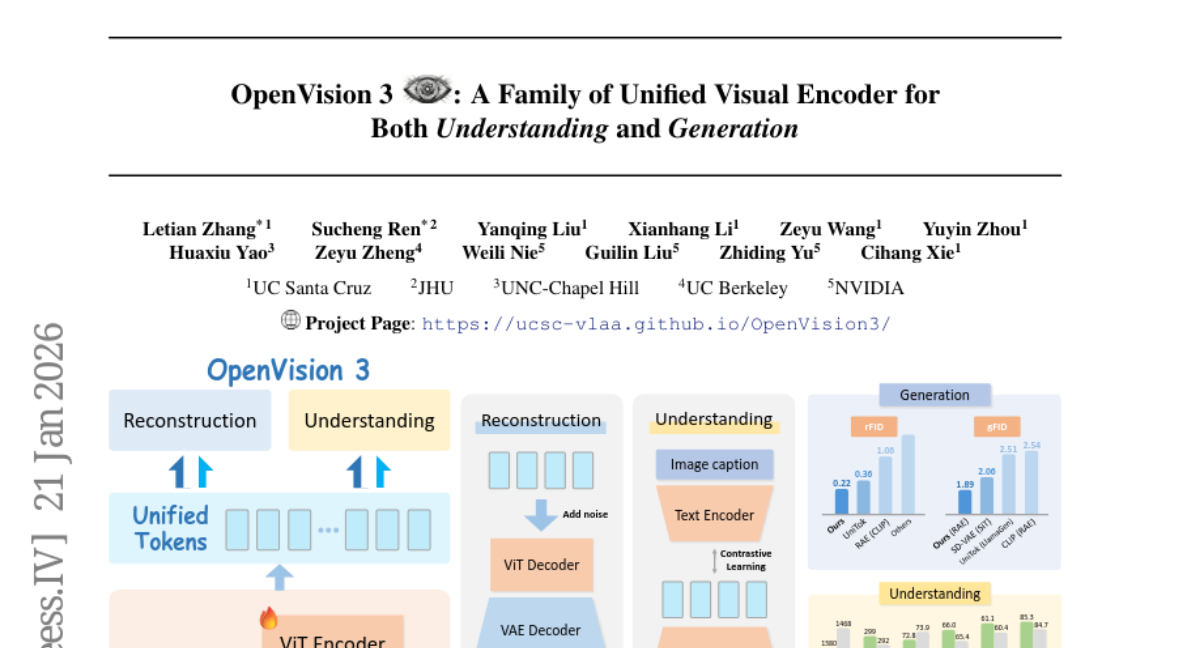
Submitted by cihangxie 16 OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation UCSC-VLAA 2
Submitted by songtingyu 13 Rethinking Composed Image Retrieval Evaluation: A Fine-Grained Benchmark from Image Editing · 9 authors 1 2
Submitted by taesiri 10 Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning NVIDIA 2
Submitted by Raymond-Qiancx 10 PROGRESSLM: Towards Progress Reasoning in Vision-Language Models · 7 authors 68 2
Submitted by Remy 8 ActionMesh: Animated 3D Mesh Generation with Temporal 3D Diffusion AI at Meta 81 3
Submitted by zhangjiaxin2012 4 From Passive Metric to Active Signal: The Evolving Role of Uncertainty Quantification in Large Language Models Salesforce 2
Submitted by rhachiuma 4 VIOLA: Towards Video In-Context Learning with Minimal Annotations · 3 authors 2
Submitted by rajkumarrawal 1 LLM Prompt Evaluation for Educational Applications Vanderbilt University 2
Submitted by sandyherho 1 Numba-Accelerated 2D Diffusion-Limited Aggregation: Implementation and Fractal Characterization Institut Teknologi Bandung 2 2
Submitted by ashutosh1919 1 MirrorBench: An Extensible Framework to Evaluate User-Proxy Agents for Human-Likeness SAP 10 3
Submitted by Cohaerence - Wigner's Friend as a Circuit: Inter-Branch Communication Witness Benchmarks on Superconducting Quantum Hardware · 1 authors 5 2


 LutherXD
LutherXD