Submitted by ZhuofengLi 66 Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction TIGER-Lab 49 3
Submitted by taesiri 60 Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning · 9 authors 2
Submitted by MindscapeRAG 46 MiA-Signature: Approximating Global Activation for Long-Context Understanding Tencent 3
Submitted by bond005 37 RaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation Novosibirsk State University 3 5
Submitted by linjhong 36 When to Trust Imagination: Adaptive Action Execution for World Action Models · 7 authors 3
Submitted by ChengsongHuang 28 Nonsense Helps: Prompt Space Perturbation Broadens Reasoning Exploration · 6 authors 3
Submitted by scofield7419 25 Audio-Visual Intelligence in Large Foundation Models National University of Singapore 33 3
Submitted by byliutao 24 Continuous-Time Distribution Matching for Few-Step Diffusion Distillation alibaba-inc 58 4
Submitted by lucazhou2000 16 StraTA: Incentivizing Agentic Reinforcement Learning with Strategic Trajectory Abstraction · 8 authors 5 2
Submitted by ethanning 11 Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes Carnegie Mellon University 3 3
Submitted by CuSO4-Chen 10 A^2TGPO: Agentic Turn-Group Policy Optimization with Adaptive Turn-level Clipping Tencent 5 4
Submitted by wtl666wtl 10 Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key · 7 authors 4
Submitted by taesiri 9 AI Co-Mathematician: Accelerating Mathematicians with Agentic AI · 18 authors 2
Submitted by centaurus-alpha 7 UniPool: A Globally Shared Expert Pool for Mixture-of-Experts CUHK 5 4
Submitted by pengxiang 7 ReflectDrive-2: Reinforcement-Learning-Aligned Self-Editing for Discrete Diffusion Driving · 10 authors 3
Submitted by taiganga 7 TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding AI4Data 1 3
Submitted by LazySheeep 5 SwiftI2V: Efficient High-Resolution Image-to-Video Generation via Conditional Segment-wise Generation · 6 authors 33 4
Submitted by J017athan 5 The Granularity Axis: A Micro-to-Macro Latent Direction for Social Roles in Language Models University of Hong Kong 4 3
Submitted by jt-zhang 4 KernelBench-X: A Comprehensive Benchmark for Evaluating LLM-Generated GPU Kernels Tsinghua University 15 4
Submitted by envomp 3 The Scaling Properties of Implicit Deductive Reasoning in Transformers Applied AI group of the Tallinn University of Technology 3
Submitted by zyzeng 3 Balanced Aggregation: Understanding and Fixing Aggregation Bias in GRPO OpenMOSS 2
Submitted by gxx27 2 BioTool: A Comprehensive Tool-Calling Dataset for Enhancing Biomedical Capabilities of Large Language Models University of California San Diego 2 3
Submitted by hdong51 2 Are We Making Progress in Multimodal Domain Generalization? A Comprehensive Benchmark Study ETH Zurich 11 3
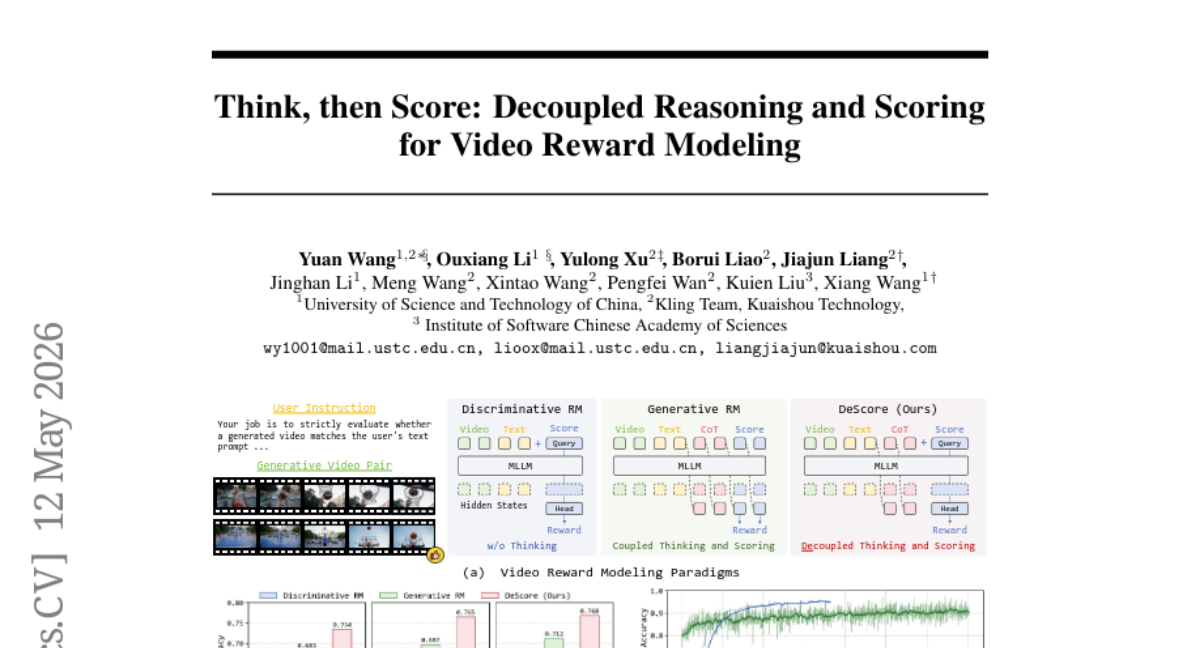
Submitted by taesiri 2 Think, then Score: Decoupled Reasoning and Scoring for Video Reward Modeling · 11 authors 2
Submitted by pmantini 2 GeoStack: A Framework for Quasi-Abelian Knowledge Composition in VLMs University of Houston 0 2
Submitted by SushantGautam 2 When No Benchmark Exists: Validating Comparative LLM Safety Scoring Without Ground-Truth Labels Simula Metropolitan Center for Digital Engineering (SimulaMet) 14 3
Submitted by stdKonjac 1 Sparkle: Realizing Lively Instruction-Guided Video Background Replacement via Decoupled Guidance Show Lab 6 3
Submitted by SWY666 1 EDU-CIRCUIT-HW: Evaluating Multimodal Large Language Models on Real-World University-Level STEM Student Handwritten Solutions · 6 authors 4 3


 ZhuofengLi
ZhuofengLi