Accurate & efficient vision models, ops and systems
AI & ML interests
Computer Vision, AI, Machine Learning
Recent Activity
View all activity
Papers

IMG: Calibrating Diffusion Models via Implicit Multimodal Guidance
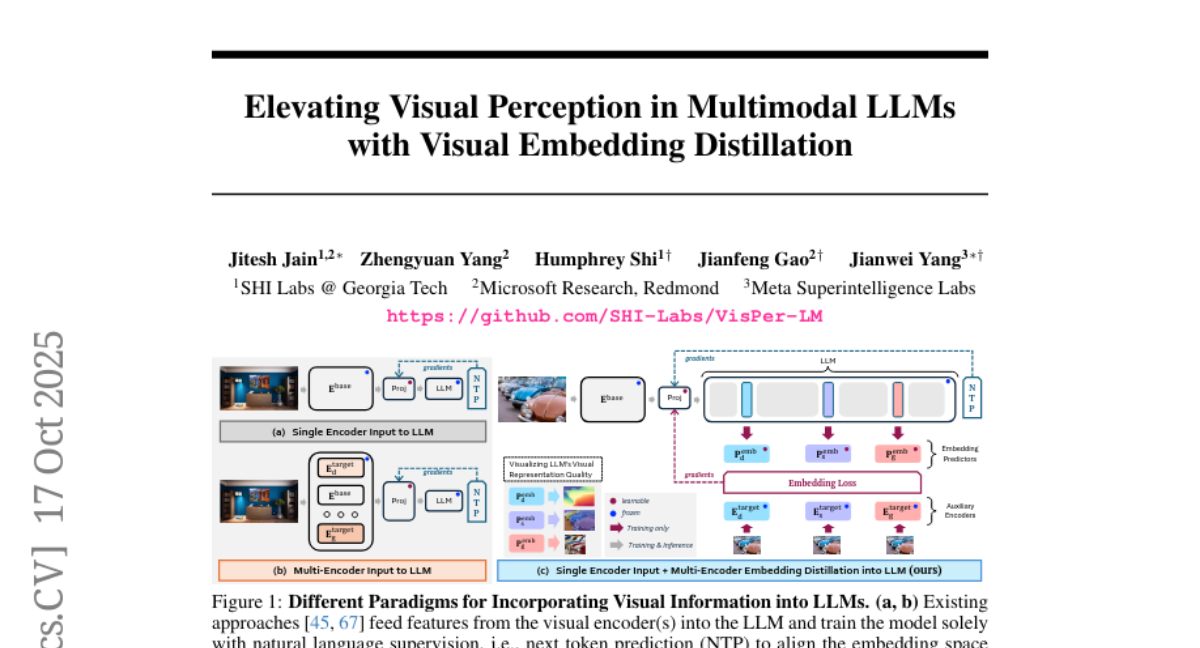
OLA-VLM: Elevating Visual Perception in Multimodal LLMs with Auxiliary Embedding Distillation
Generative AI for visual creativity
Elevating Visual Perception in Multimodal LLMs with Visual Embedding Distillation
-
VisPer-LM
🔍5Visualize image depth, segmentation, and generation
-

shi-labs/OLA-VLM-CLIP-ViT-Llama3-8b
Image-Text-to-Text • 8B • Updated • 6 -
shi-labs/OLA-VLM-CLIP-ConvNeXT-Phi3-4k-mini
Image-Text-to-Text • 5B • Updated • 6 • 1 -
shi-labs/OLA-VLM-CLIP-ConvNeXT-Llama3-8b
Image-Text-to-Text • 9B • Updated • 4 • 1
Accurate & efficient vision models, ops and systems
Large multimodal models
Generative AI for visual creativity
Elevating Visual Perception in Multimodal LLMs with Visual Embedding Distillation
-
VisPer-LM
🔍5Visualize image depth, segmentation, and generation
-
shi-labs/OLA-VLM-CLIP-ViT-Llama3-8b
Image-Text-to-Text • 8B • Updated • 6 -
shi-labs/OLA-VLM-CLIP-ConvNeXT-Phi3-4k-mini
Image-Text-to-Text • 5B • Updated • 6 • 1 -
shi-labs/OLA-VLM-CLIP-ConvNeXT-Llama3-8b
Image-Text-to-Text • 9B • Updated • 4 • 1