
Custom Build Models
Collection
Text Generation Cook with it's GGUF • 53 items • Updated • 2
The QwQ-LCoT-3B-Instruct model is a lightweight, instruction-tuned language model designed for complex reasoning and explanation tasks. It is fine-tuned on the Qwen2.5-3B-Instruct base model using the QwQ-LongCoT-130K dataset, focusing on long-chain-of-thought (LCoT) reasoning for enhanced logical comprehension and detailed output generation.
| File Name | Size | Description | Upload Status |
|---|---|---|---|
.gitattributes |
1.57 kB | Specifies LFS tracking for large files. | Uploaded |
README.md |
267 Bytes | Basic project information file. | Updated |
added_tokens.json |
657 Bytes | Custom tokens added to the tokenizer. | Uploaded |
config.json |
859 Bytes | Configuration file for the model. | Uploaded |
generation_config.json |
281 Bytes | Configuration file for text generation settings. | Uploaded |
merges.txt |
1.82 MB | Contains the byte-pair encoding (BPE) merges. | Uploaded |
pytorch_model-00001-of-00002.bin |
4.96 GB | First shard of the model weights in PyTorch format. | Uploaded (LFS) |
pytorch_model-00002-of-00002.bin |
1.21 GB | Second shard of the model weights in PyTorch format. | Uploaded (LFS) |
pytorch_model.bin.index.json |
36 kB | Index mapping for sharded model weights. | Uploaded |
special_tokens_map.json |
644 Bytes | Maps special tokens to their roles. | Uploaded |
tokenizer.json |
11.4 MB | Serialized tokenizer data. | Uploaded (LFS) |
tokenizer_config.json |
7.73 kB | Tokenizer configuration settings. | Uploaded |
vocab.json |
2.78 MB | Vocabulary file for the tokenizer. | Uploaded |
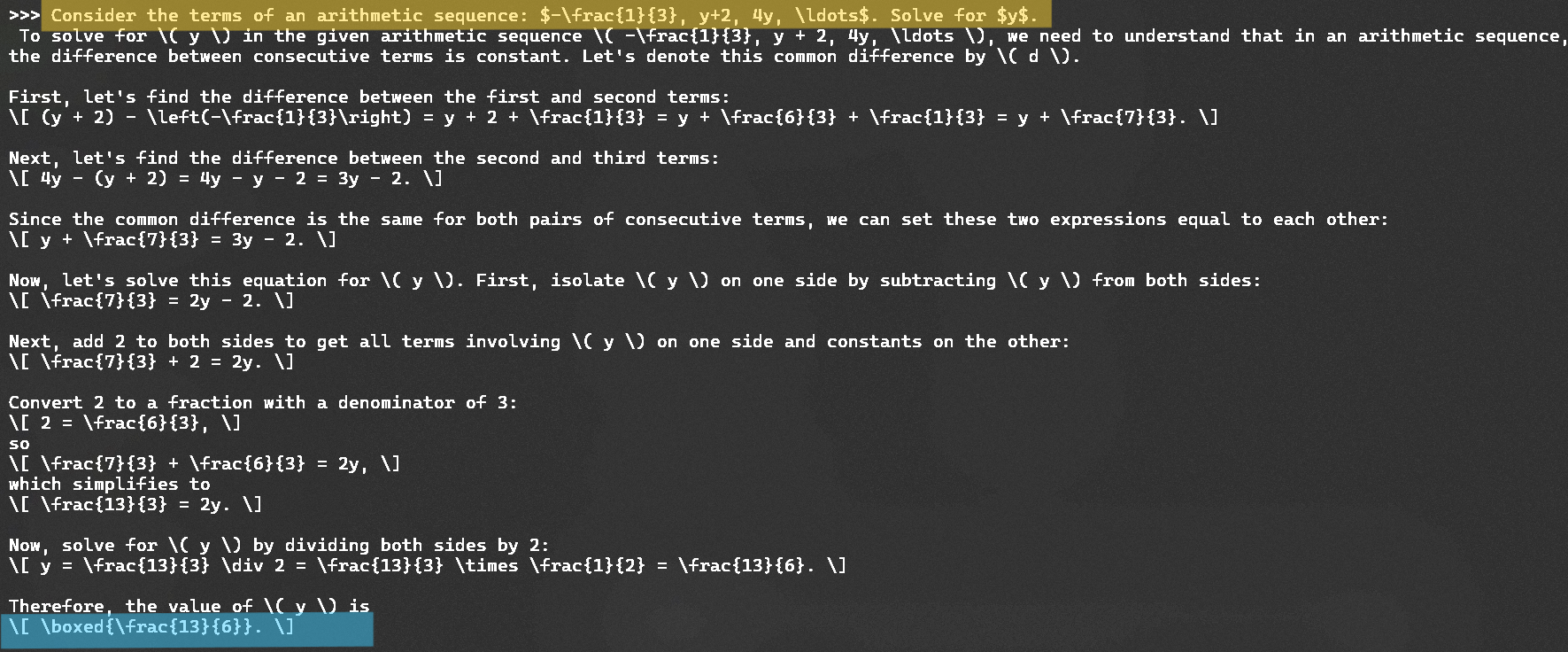
Long Chain-of-Thought Reasoning:
Lightweight and Efficient:
Instruction Optimization:
Text Generation:
Reasoning Tasks:
Educational Assistance:
Dialogue and Summarization:
Setup: Download all model files and ensure compatibility with the Hugging Face Transformers library.
Loading the Model:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prithivMLmods/QwQ-LCoT-3B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
Generate Long-Chain Reasoning Outputs:
input_text = "Explain the process of photosynthesis step-by-step."
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs, max_length=300, temperature=0.5)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Customize Output Generation:
Modify the generation_config.json file for different scenarios:
temperature: Controls randomness (lower = deterministic, higher = creative). max_length: Sets response length. top_p: Adjusts sampling for diversity in outputs.Base model
Qwen/Qwen2.5-3B